OuteTTSとは
テキストエンコーダー → LLMに音声構成トークンを出力させる → デコーダーでトークンから音声復元
GitHub

GitHub - edwko/OuteTTS: Interface for OuteTTS models.
Interface for OuteTTS models. Contribute to edwko/OuteTTS development by creating an account on GitHub.
目次
中身
まず推論
import outetts
# モデルの設定を行う
model_config = outetts.HFModelConfig_v2(
model_path="OuteAI/OuteTTS-0.3-1B", # モデルのパスを指定
tokenizer_path="OuteAI/OuteTTS-0.3-1B" # トークナイザーのパスを指定
)
# インターフェースを初期化
interface = outetts.InterfaceHF(model_version="0.3", cfg=model_config)
# ボイスクローンのために話者プロファイルを作成することが可能(すべてのバックエンドで互換性あり)
# speaker = interface.create_speaker(audio_path="path/to/audio/file.wav") # オーディオファイルから話者プロファイルを作成
# interface.save_speaker(speaker, "speaker.json") # 話者プロファイルを保存
# speaker = interface.load_speaker("speaker.json") # 保存済みの話者プロファイルを読み込む
# 利用可能なデフォルト話者を表示
interface.print_default_speakers()
# デフォルトの話者を読み込む
speaker = interface.load_default_speaker(name="en_male_1")
# 音声を生成
gen_cfg = outetts.GenerationConfig(
text="もしそれでも問題が続く場合、音声生成ライブラリ自体でサンプルレートを指定している可能性もある", # 合成するテキスト
temperature=0.1, # テンプレチャー(生成のランダム性を調整)
repetition_penalty=1.1, # 繰り返し抑制のペナルティ値
max_length=4096, # 生成される音声の最大長
speaker=speaker, # 話者プロファイルを指定
# voice_characteristics="upbeat enthusiasm, friendliness, clarity, professionalism, and trustworthiness" # 声の特徴を指定可能(任意)
)
output = interface.generate(config=gen_cfg)
# 生成された音声をファイルに保存
output.save("output.wav")
import wave
# 保存された音声ファイルのパス
file_path = "output.wav"
# 音声ファイルを開く
with wave.open(file_path, 'rb') as audio_file:
# サンプルレート(Hz)を取得
sample_rate = audio_file.getframerate()
print(f"The sample rate of the audio file is {sample_rate} Hz.")
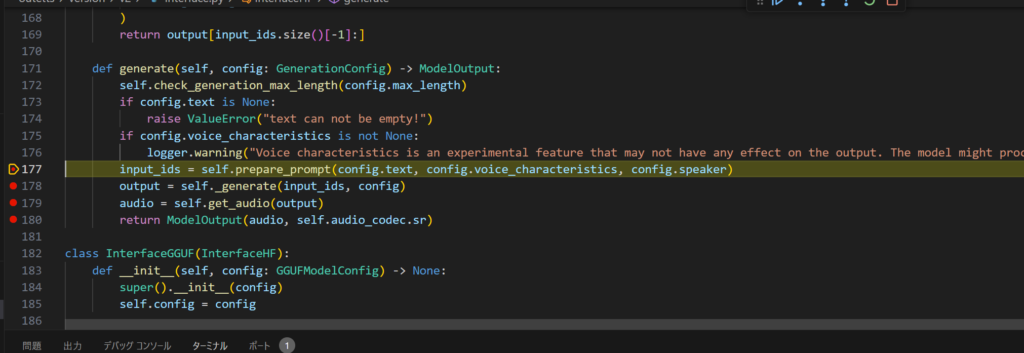
ジェネレーターはインプットIDにしてモデルに入れる、出てきたのをデコードで返す、とシンプル。
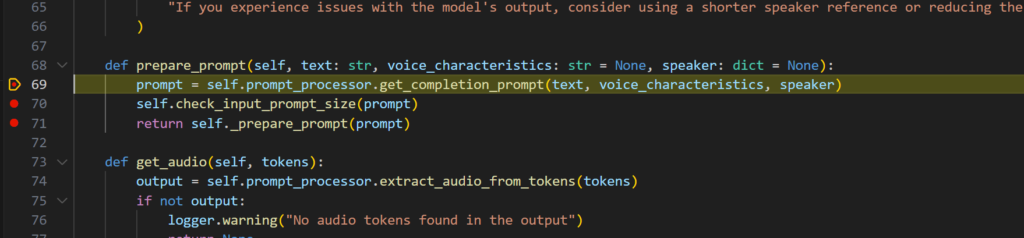
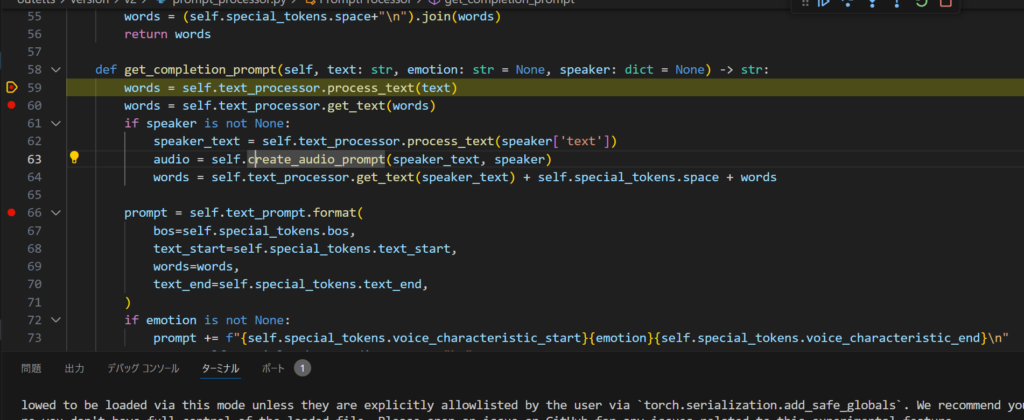
get_completion_promptがプロンプト作成本体。
wordsで単語単位でパース。
speakerがいる場合はauidoトークンを付与。
面白いのが参照音声を使わないでトークンで話者スタイルを決めている。
モデルがどこまで保持できるかはパラメーターもあり疑問だが制限なしかつ音声も保持管理が必要ないため手軽さはよい。
モデル自体はトークン掃き出してそれをテンソルにしてデコードして音声化。
また、voice_characteristics=”upbeat enthusiasm, friendliness, clarity, professionalism, and trustworthinesとあるように声の特徴もスタイルで指定できる。
そしてトークン生成をLLMで行うことによってrepetition_penaltyやtemperatureを使うことができるのもよい。
repetition_penaltyをあげれば起伏が激しい音声になったり平坦にしたりとコントロールしやすそう。
まとめ
音声アライメントガイド(文字ごとにイントネーション割り振り)をせずとも高コントロール可能な仕組みができていて面白い。シンプルかつ強力なため期待できそう。







