概要
GAN(Generative Adversarial Network、生成的対向ネットワーク)は、2014年にイアン・グッドフェローらによって提案された、データを生成するための機械学習モデルの一種です。GANは「生成モデル」と「識別モデル」という2つのモデルが互いに競争しながら学習する仕組みで、以下のように動作します。
生成モデル(ジェネレーター)
ジェネレーターは、ランダムなノイズから「偽のデータ」を生成します。この偽データは、例えば画像生成のGANでは本物の画像のように見えることを目指して作成されます。
識別モデル(ディスクリミネーター)
ディスクリミネーターは、本物のデータとジェネレーターが作った偽のデータを見分ける役割を持ちます。ディスクリミネーターは「本物」と「偽物」を区別できるように学習します。
本記事では実際に手書き数字のMNISTデータセットを学習させてどのようになるか確認します。
コード
# 必要なライブラリのインポート
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os # フォルダ作成用
# デバイスの設定 (GPUが利用可能な場合はGPU、そうでない場合はCPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# データ変換の定義
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# MNISTデータセットのダウンロードとデータローダーの設定
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Generatorの定義
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512, 1024),
nn.ReLU(True),
nn.Linear(1024, output_dim),
nn.Tanh()
)
def forward(self, x):
return self.model(x)
# Discriminatorの定義
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
# ハイパーパラメータの設定
z_dim = 100 # ノイズの次元数
img_dim = 28 * 28 # MNIST画像の次元数(28x28=784)
learning_rate = 0.0002
# GeneratorとDiscriminatorのインスタンス化、デバイスへの移動
generator = Generator(input_dim=z_dim, output_dim=img_dim).to(device)
discriminator = Discriminator(input_dim=img_dim).to(device)
# 最適化アルゴリズム
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate)
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 損失関数
criterion = nn.BCELoss()
# 画像保存関数(各エポックごとに10枚保存)
def save_generated_images(epoch, num_images=10, folder='generated_images'):
os.makedirs(folder, exist_ok=True) # フォルダが存在しない場合は作成
z = torch.randn(num_images, z_dim).to(device) # num_images個のノイズベクトルを生成
fake_imgs = generator(z).view(-1, 1, 28, 28).to("cpu") # 生成画像を整形し、CPUに戻す
fake_imgs = (fake_imgs + 1) / 2 # ピクセル値を[0, 1]にスケール
grid = torchvision.utils.make_grid(fake_imgs, nrow=5) # 5x2のグリッドで表示
file_path = os.path.join(folder, f"epoch_{epoch+1}.png") # ファイルパスを設定
plt.figure(figsize=(10, 4))
plt.imshow(grid.permute(1, 2, 0).detach().numpy())
plt.axis('off')
plt.savefig(file_path) # 画像をファイルに保存
plt.close() # プロットを閉じる
# トレーニングの設定
num_epochs = 50
for epoch in range(num_epochs):
for real_imgs, _ in train_loader:
# データをデバイスに移動
real_imgs = real_imgs.view(real_imgs.size(0), -1).to(device)
real_labels = torch.ones(real_imgs.size(0), 1).to(device)
fake_labels = torch.zeros(real_imgs.size(0), 1).to(device)
# Discriminatorのトレーニング(本物と偽物を識別)
optimizer_D.zero_grad()
# 本物の画像の損失
outputs = discriminator(real_imgs)
d_loss_real = criterion(outputs, real_labels)
# 偽物の画像の損失
z = torch.randn(real_imgs.size(0), z_dim).to(device) # ノイズもデバイスに移動
fake_imgs = generator(z)
outputs = discriminator(fake_imgs.detach()) # detachでGeneratorの勾配は更新しない
d_loss_fake = criterion(outputs, fake_labels)
# Discriminatorの合計損失と更新
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
optimizer_D.step()
# Generatorのトレーニング(偽物を本物と誤認させる)
optimizer_G.zero_grad()
outputs = discriminator(fake_imgs)
g_loss = criterion(outputs, real_labels)
# Generatorの損失と更新
g_loss.backward()
optimizer_G.step()
print(f"Epoch [{epoch+1}/{num_epochs}], d_loss: {d_loss.item():.4f}, g_loss: {g_loss.item():.4f}")
# 各エポックごとに10枚の生成画像を保存
save_generated_images(epoch, num_images=10, folder='generated_images')
結果
上記のとおりepochを50まで回した結果です。
Epoch [1/50], d_loss: 0.0566, g_loss: 10.4132
Epoch [2/50], d_loss: 0.0672, g_loss: 7.2213
Epoch [3/50], d_loss: 0.2609, g_loss: 3.6743
Epoch [4/50], d_loss: 0.3130, g_loss: 10.1963
Epoch [5/50], d_loss: 0.0203, g_loss: 8.1622
Epoch [6/50], d_loss: 0.1389, g_loss: 6.9700
Epoch [7/50], d_loss: 0.0043, g_loss: 10.8207
Epoch [8/50], d_loss: 0.0278, g_loss: 6.0416
Epoch [9/50], d_loss: 0.1329, g_loss: 7.9730
Epoch [10/50], d_loss: 0.2260, g_loss: 4.7434
Epoch [11/50], d_loss: 0.2017, g_loss: 6.4528
Epoch [12/50], d_loss: 0.1051, g_loss: 3.3526
Epoch [13/50], d_loss: 0.1734, g_loss: 5.9209
Epoch [14/50], d_loss: 0.3976, g_loss: 5.4625
Epoch [15/50], d_loss: 0.1002, g_loss: 6.7051
Epoch [16/50], d_loss: 0.1129, g_loss: 3.9182
Epoch [17/50], d_loss: 0.3493, g_loss: 3.2061
Epoch [18/50], d_loss: 0.1807, g_loss: 3.5808
Epoch [19/50], d_loss: 0.2168, g_loss: 3.3772
Epoch [20/50], d_loss: 0.5591, g_loss: 2.6476
Epoch [21/50], d_loss: 0.3900, g_loss: 3.8372
Epoch [22/50], d_loss: 0.3020, g_loss: 3.0853
Epoch [23/50], d_loss: 0.4162, g_loss: 3.6674
Epoch [24/50], d_loss: 0.1737, g_loss: 2.6148
Epoch [25/50], d_loss: 0.5323, g_loss: 2.9985
Epoch [26/50], d_loss: 0.6900, g_loss: 3.8382
Epoch [27/50], d_loss: 0.6474, g_loss: 2.1668
Epoch [28/50], d_loss: 0.3230, g_loss: 2.4905
Epoch [29/50], d_loss: 0.9136, g_loss: 1.9325
Epoch [30/50], d_loss: 0.2749, g_loss: 3.3031
Epoch [31/50], d_loss: 0.8904, g_loss: 2.5821
Epoch [32/50], d_loss: 0.5742, g_loss: 1.7155
Epoch [33/50], d_loss: 0.7564, g_loss: 2.0241
Epoch [34/50], d_loss: 0.5066, g_loss: 2.5349
Epoch [35/50], d_loss: 0.6034, g_loss: 1.8526
Epoch [36/50], d_loss: 0.8636, g_loss: 2.2440
Epoch [37/50], d_loss: 0.5999, g_loss: 2.2265
Epoch [38/50], d_loss: 0.7234, g_loss: 2.2666
Epoch [39/50], d_loss: 0.5331, g_loss: 1.8005
Epoch [40/50], d_loss: 1.0194, g_loss: 2.7950
Epoch [41/50], d_loss: 0.7151, g_loss: 1.6714
Epoch [42/50], d_loss: 0.6679, g_loss: 1.5930
Epoch [43/50], d_loss: 1.0183, g_loss: 2.0514
Epoch [44/50], d_loss: 1.1098, g_loss: 1.1370
Epoch [45/50], d_loss: 0.9919, g_loss: 1.5936
Epoch [46/50], d_loss: 0.9348, g_loss: 1.6760
Epoch [47/50], d_loss: 0.7383, g_loss: 1.7330
Epoch [48/50], d_loss: 0.8078, g_loss: 1.9343
Epoch [49/50], d_loss: 0.7770, g_loss: 1.9625
Epoch [50/50], d_loss: 0.5050, g_loss: 2.1323


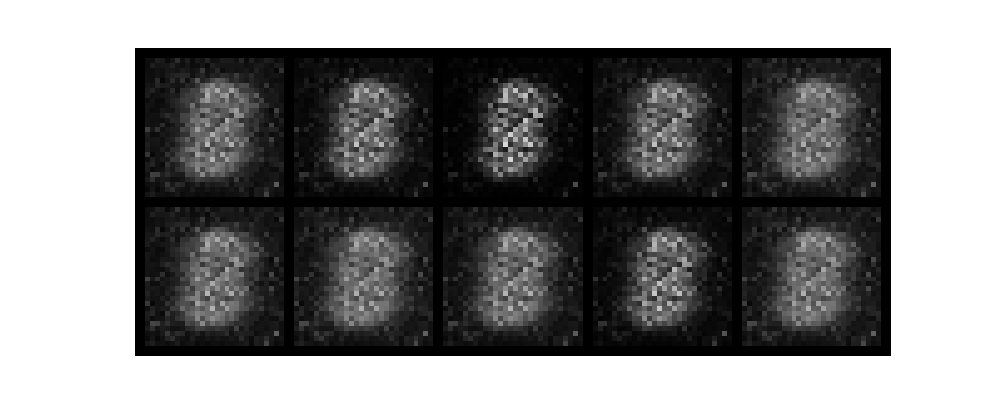
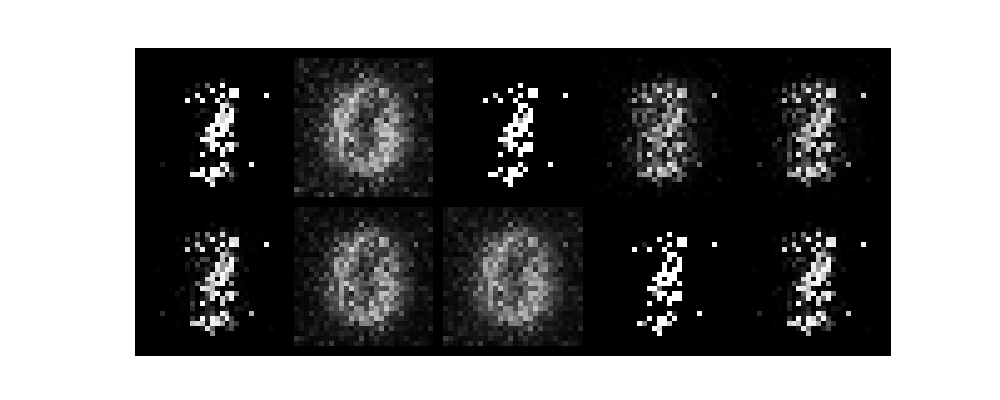

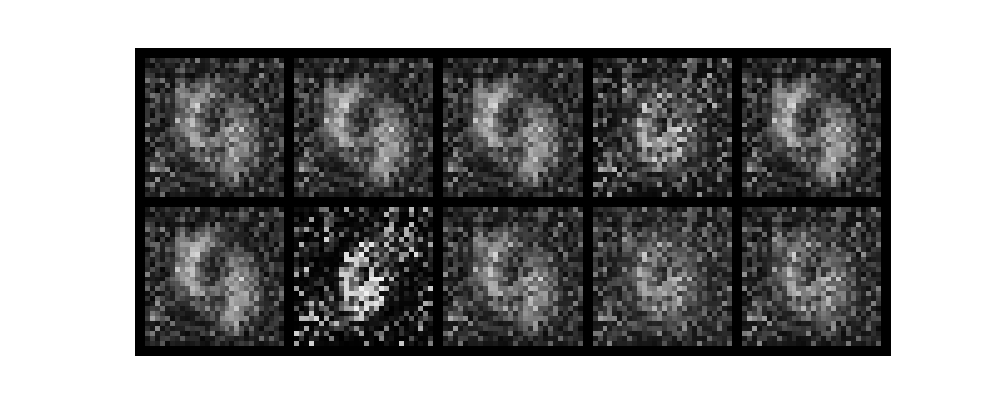

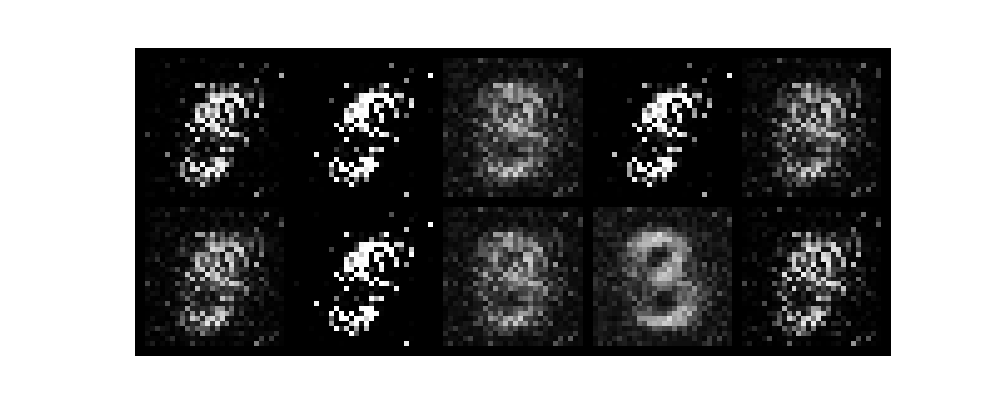

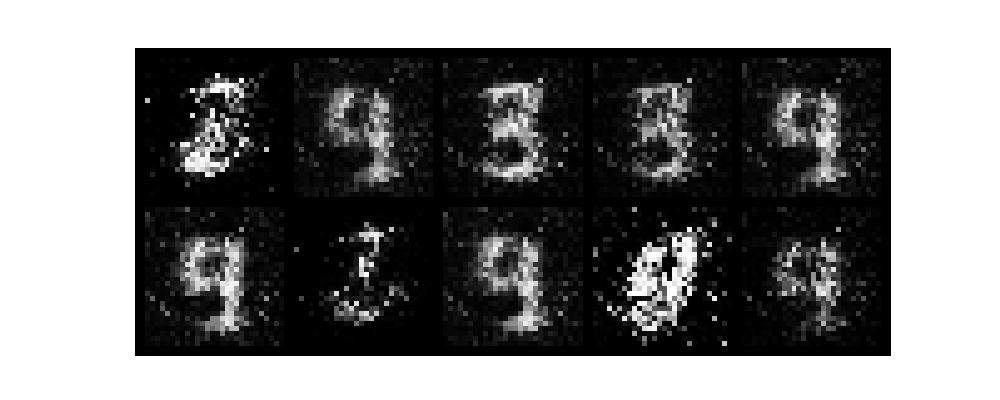
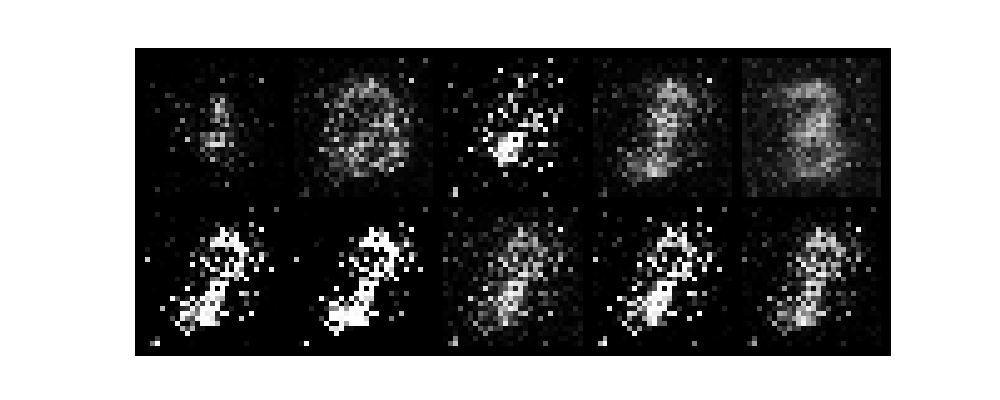

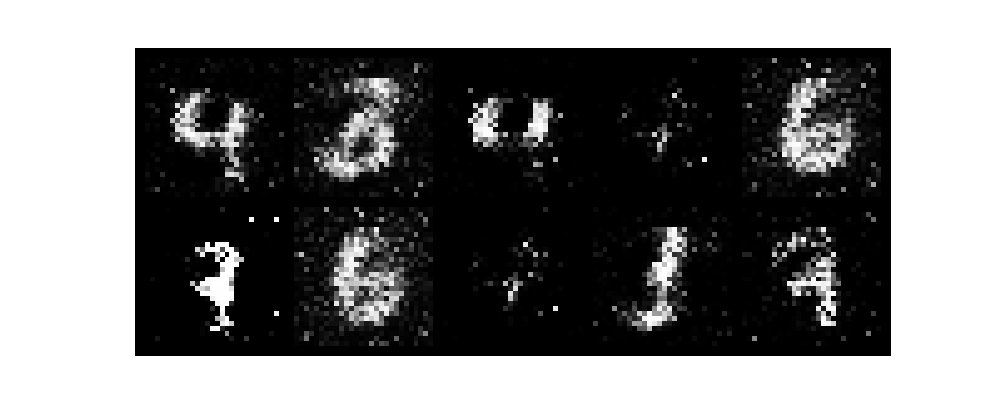

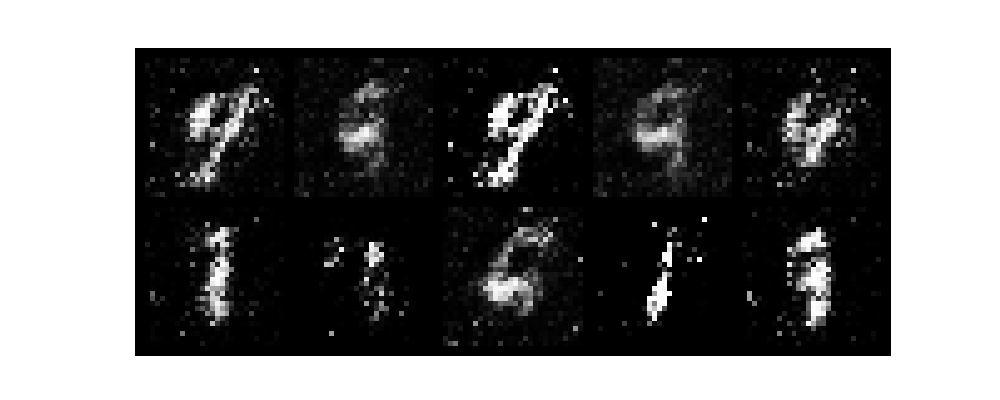

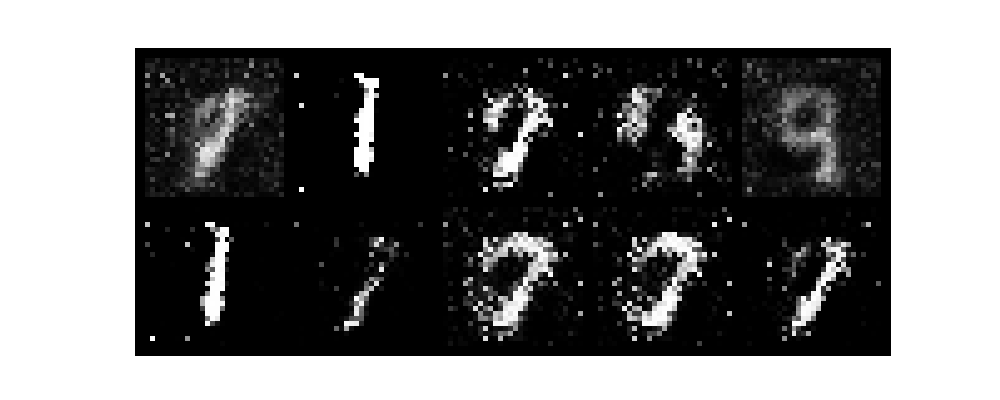





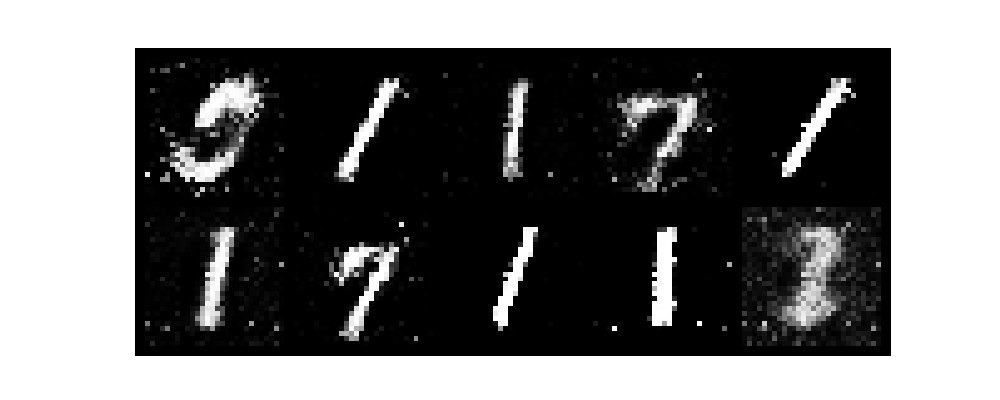















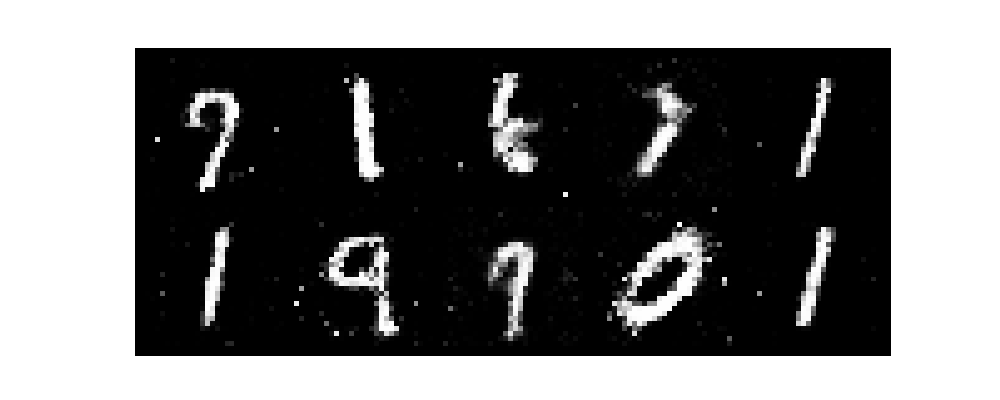











epochがすすむごとに数字がだんだんと認識できるようになり、無事手書き数字を生成できました。
また、今回はテンソルボードを起動させていないです。そのためわかりづらいですがGANのlossは生成モデルと識別モデルが拮抗する関係で変動します。
まとめ
今回はGANについてご紹介させていただきました。
GANは非常にリアルな画像生成や音声生成に成功し、現在ではアートの自動生成やフェイク画像・動画の作成、医療や自動運転など多くの分野で利用されています。
画像、テキスト、音声など汎用性が高い学習方法のため、引き続き理解していき覚えたいです。







