cogvideox-factoryは本家のcogvideoxのファインチューニングをメモリを抑えるようにしたファインチューニング用の改造版です。今回はLora形式でCogVideoX-5bをファインチューニングします。この記事はファインチューニングが長すぎて暇だったので書いてます・・・

注意点
使っているライブラリがLinux依存が多いためLinux用になっています。
WIndowsの方はUSBメモリなどにUBUNTUを入れないと試すのは厳しいようでした。
手順
- リポジトリを落とす
-
好きなところでgit clone https://github.com/a-r-r-o-w/cogvideox-factory.git
- VENVでrequirements.txtを使ってライブラリをセット。
-
好きなように作ればいい(コマンドでも)のですが私はVScodeのCtrl Sfiht Pの環境作成より作っています。
そのままpipもしなくても選択するだけでrequirementsをセットしてくれるので楽です。
- diffusersのインストール
-
そのままpip install git+https://github.com/huggingface/diffusers
- ファインチューニング用のデータセット準備
-
公式が載せているのでまずはなんとなくで。
huggingface-cli download \
–repo-type dataset Wild-Heart/Disney-VideoGeneration-Dataset \
–local-dir video-dataset-disney必要なのはvideosにデータ、プロンプトと動画パスリストのtxtだけですね。
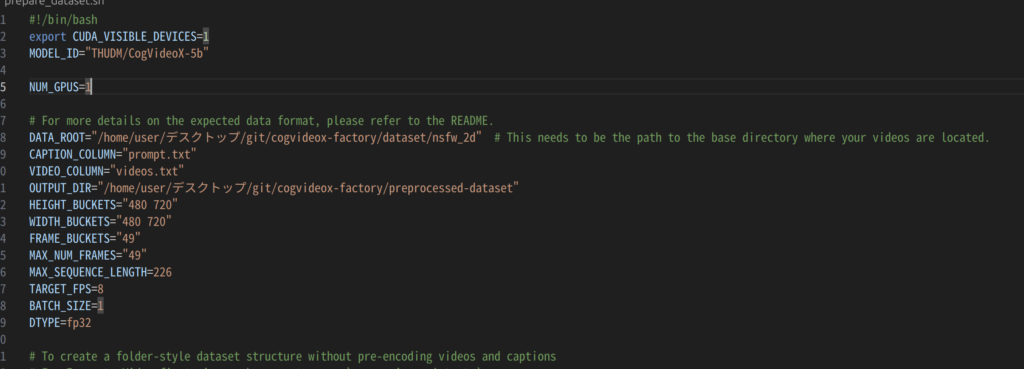
- prepare_dataset.shを実行
-
公式になぜか書かれていませんが前処理で必要です。
変更箇所はパスあたり。バケットはどうやらリサイズしてくれるようです。
が、私は面倒なのでgptなどに前処理コードを作らせて揃えました。
GitHubFile not found · a-r-r-o-w/finetrainers Memory-optimized training library for diffusion models - File not found · a-r-r-o-w/finetrainersデータセットはいくつか入力次元を揃えるための成約があるようです。
解像度は32で割り切れる数、フレーム数は4で割れる数にしてねとのこと。
一応これさえ守ればどのサイズでも問題はないようです。(メモリや作りたいものと相談してください)
./prepare_dataset.shで実行。
- train_text_to_video_lora.shを実行
-
前処理が終わるとこんな感じでoutputに指定したフォルダに出てきます。(nsfwデータですいません)
サイズは縦720横480で揃えました。作ったサイズに応じて後述するパラメーターのバケットを適時直してください。
-
-
エラーがなくおわった場合はまたtrain_text_to_video_lora.shを一部パラメーターを直してください。
私はこんな感じで変えました。また、RTX8000を使っていましたがbf16に対応していないので、fp16へ変更しています。
export TORCH_LOGS="+dynamo,recompiles,graph_breaks" export TORCHDYNAMO_VERBOSE=1 export WANDB_MODE="offline" export NCCL_P2P_DISABLE=1 export TORCH_NCCL_ENABLE_MONITORING=0 GPU_IDS="1,0" # Training Configurations # Experiment with as many hyperparameters as you want! LEARNING_RATES=("1e-4" "1e-3") LR_SCHEDULES=("cosine_with_restarts") OPTIMIZERS=("adamw" "adam") MAX_TRAIN_STEPS=("3000") # Single GPU uncompiled training ACCELERATE_CONFIG_FILE="accelerate_configs/uncompiled_1.yaml" # Absolute path to where the data is located. Make sure to have read the README for how to prepare data. # This example assumes you downloaded an already prepared dataset from HF CLI as follows: # huggingface-cli download --repo-type dataset Wild-Heart/Disney-VideoGeneration-Dataset --local-dir /path/to/my/datasets/disney-dataset DATA_ROOT="/home/user/デスクトップ/git/cogvideox-factory/preprocessed-dataset" CAPTION_COLUMN="prompts.txt" VIDEO_COLUMN="videos.txt" MODEL_PATH="THUDM/CogVideoX-5b" # Set ` --load_tensors ` to load tensors from disk instead of recomputing the encoder process. # Launch experiments with different hyperparameters for learning_rate in "${LEARNING_RATES[@]}"; do for lr_schedule in "${LR_SCHEDULES[@]}"; do for optimizer in "${OPTIMIZERS[@]}"; do for steps in "${MAX_TRAIN_STEPS[@]}"; do output_dir="./cogvideox-lora__optimizer_${optimizer}__steps_${steps}__lr-schedule_${lr_schedule}__learning-rate_${learning_rate}/" cmd="accelerate launch --config_file $ACCELERATE_CONFIG_FILE --gpu_ids $GPU_IDS training/cogvideox_text_to_video_lora.py \ --pretrained_model_name_or_path $MODEL_PATH \ --data_root $DATA_ROOT \ --caption_column $CAPTION_COLUMN \ --video_column $VIDEO_COLUMN \ --id_token danbooru_anime_nsfw \ --height_buckets 720 \ --width_buckets 480 \ --frame_buckets 49 \ --dataloader_num_workers 8 \ --pin_memory \ --validation_prompt \"danbooru_anime_nsfw girl, blue eyes, blush, braid, breasts, censored, collarbone, completely nude, deep skin, grabbing own breast, hair between eyes, hair ribbon, huge breasts, long hair, looking at viewer, mosaic censoring, multicolored hair, nipples, nude, open mouth, paizuri, penis, pink eyes, pink hair, ribbon, smile, solo focus, streaked hair, two-tone eyes, white ribbon\" \ --validation_prompt_separator ::: \ --num_validation_videos 1 \ --validation_epochs 10 \ --seed 42 \ --rank 128 \ --lora_alpha 128 \ --mixed_precision fp16 \ --output_dir $output_dir \ --max_num_frames 49 \ --train_batch_size 1 \ --max_train_steps $steps \ --checkpointing_steps 100 \ --gradient_accumulation_steps 1 \ --gradient_checkpointing \ --learning_rate $learning_rate \ --lr_scheduler $lr_schedule \ --lr_warmup_steps 400 \ --lr_num_cycles 1 \ --enable_slicing \ --enable_tiling \ --enable_model_cpu_offload \ --load_tensors \ --optimizer $optimizer \ --beta1 0.9 \ --beta2 0.95 \ --weight_decay 0.001 \ --max_grad_norm 1.0 \ --allow_tf32 \ --report_to wandb \ --nccl_timeout 1800" echo "Running command: $cmd" eval $cmd echo -ne "-------------------- Finished executing script --------------------\n\n" done done done done -
問題なく実行できたばあいはそのまま訓練モードに。いい感じにできるまで待ちましょう。
また、そのままメモリ関連を削らない場合は24gbに収まります。
が勾配周りを削除すると消費が48GBでも乗らなかったです。

所感
Readmeが不親切なところがあるので思ったより動かすまで時間がかかった。また、現環境はRTX3090とRTX8000だが旧世代なところもありbf16の必要性が高まっているなと感じた。年末頃に5090が32GBで出た場合はW制限をかけて2台運用を検討してます。(db上だと計算速度が3,4倍違うので現在1step40sからかなり高速化できそうかなと)
また、2bより上の5bとはいえgradient_accumulation_stepsとLoraをかけないとファインチューニングできないとこは厳しいですね。一応24gbでもファインチューニングできるようになったがトレードオフとして訓練速度が犠牲になりすぎているかなと。
とはいえやはり。ローカルで、それなりの品質の動画生成モデルのファインチューニングができるようになったのはかなり良いですね。現状テキストと画像はもう極まっている(商用レベルに使える)と思っているので、音声と動画があとGPUリソース的に3年ほどしたら民主化するのかなと思っています。







